Session 20: Cleaning up variables names, and other wrangling
On your marks, get set, bake!

Prep homework
Basic computer setup
-
If you didn’t already do this, please follow the Code Club Computer Setup instructions, which also has pointers for if you’re new to R or RStudio.
-
If you’re able to do so, please open RStudio a bit before Code Club starts – and in case you run into issues, please join the Zoom call early and we’ll help you troubleshoot.
-
You can use R locally, or at OSC. You can find instructions if you are having trouble here.
Getting Started
RMarkdown for today’s session
# directory for Code Club Session 20:
dir.create("S20")
# directory for our RMarkdown
# ("recursive" to create two levels at once.)
dir.create("S20/Rmd/")
# save the url location for today's script
todays_Rmd <-
'https://raw.githubusercontent.com/biodash/biodash.github.io/master/content/codeclub/20_cleaning-up/CleaningUp.Rmd'
# indicate the name of the new script file
Session20_Rmd <- "S20/Rmd/CleaningUp.Rmd"
# go get that file!
download.file(url = todays_Rmd,
destfile = Session20_Rmd)1 - Using regexs for wrangling

Artwork by Allison Horst
Now that we have gone through a mini-series on regular expressions, with the basics, some next level helpers, and using tidytext to make word clouds, I thought I’d talk today about some applications of this information to cleaning up your data.
To do this, we are going to practice with the palmerpenguins dataset, and get back to the bakeoff for our practice exercises.
2 - Accessing our data
First load your libraries. We will be using stringr and tidyr but those are both part of core tidyverse. We are also using a new package today called janitor which helps you “clean up” your data.
If you don’t have the package janitor, please install it.
install.packages("janitor")library(tidyverse)
library(janitor) # for cleaning up column names
library(palmerpenguins) # for penguins data
library(bakeoff) # for bakeoff dataThen we will use the package palmerpenguins and the dataset penguins_raw, which has a bit more info than penguins, which we have used previously.

Artwork by Allison Horst
3 - Variable names
There are many instances where you may have variables names and/or sample names that are messy. For example, variable names that include characters like white spaces, special characters like symbols, or begin with a number are going to give you problems with some R coding. I’ll say that you can have these non-standard variable names, but occasionally they will give you a big headache and so I’d recommend to just avoid them.
R variable “rules”:
- can contain letters, numbers, underscores (
_) and periods (.) - cannot start with a number or underscore
- shouldn’t be a “reserved” word, like if, else, function, TRUE, FALSE etc. (if you want to see them all, execute
?reservedin your console)
You can read about the tidyverse style guide if you want to learn more.
Lets look at the variable names in penguins_raw.
glimpse(penguins_raw)
#> Rows: 344
#> Columns: 17
#> $ studyName <chr> "PAL0708", "PAL0708", "PAL0708", "PAL0708", "PAL…
#> $ `Sample Number` <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 1…
#> $ Species <chr> "Adelie Penguin (Pygoscelis adeliae)", "Adelie P…
#> $ Region <chr> "Anvers", "Anvers", "Anvers", "Anvers", "Anvers"…
#> $ Island <chr> "Torgersen", "Torgersen", "Torgersen", "Torgerse…
#> $ Stage <chr> "Adult, 1 Egg Stage", "Adult, 1 Egg Stage", "Adu…
#> $ `Individual ID` <chr> "N1A1", "N1A2", "N2A1", "N2A2", "N3A1", "N3A2", …
#> $ `Clutch Completion` <chr> "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "No", …
#> $ `Date Egg` <date> 2007-11-11, 2007-11-11, 2007-11-16, 2007-11-16,…
#> $ `Culmen Length (mm)` <dbl> 39.1, 39.5, 40.3, NA, 36.7, 39.3, 38.9, 39.2, 34…
#> $ `Culmen Depth (mm)` <dbl> 18.7, 17.4, 18.0, NA, 19.3, 20.6, 17.8, 19.6, 18…
#> $ `Flipper Length (mm)` <dbl> 181, 186, 195, NA, 193, 190, 181, 195, 193, 190,…
#> $ `Body Mass (g)` <dbl> 3750, 3800, 3250, NA, 3450, 3650, 3625, 4675, 34…
#> $ Sex <chr> "MALE", "FEMALE", "FEMALE", NA, "FEMALE", "MALE"…
#> $ `Delta 15 N (o/oo)` <dbl> NA, 8.94956, 8.36821, NA, 8.76651, 8.66496, 9.18…
#> $ `Delta 13 C (o/oo)` <dbl> NA, -24.69454, -25.33302, NA, -25.32426, -25.298…
#> $ Comments <chr> "Not enough blood for isotopes.", NA, NA, "Adult…What you can see is that there are variable names here that don’t comply with the “rules” I just indicated. How can that be?! You can see for the variable Sample Number that it is surrounded by backticks. This is how R know that this is a variable name.
Okay, so who cares? If you want to call that particular variable, you will have to put it in backticks. For example:
# this doesn't work
penguins_raw %>%
select(Sample Number)# this works but is clunky
penguins_raw %>%
select(`Sample Number`)
#> # A tibble: 344 × 1
#> `Sample Number`
#> <dbl>
#> 1 1
#> 2 2
#> 3 3
#> 4 4
#> 5 5
#> 6 6
#> 7 7
#> 8 8
#> 9 9
#> 10 10
#> # … with 334 more rowsAnd, this is using tidyverse functions - there will be other situations where you will get non-solvable errors because of your variable names.
tl;dr just make your variable names R compliant, there are lots of other harder things you’re going to be doing with coding, so just make this easier for yourself.
Using clean_names()

Artwork by Allison Horst
You may be thinking now, okay but what happens if someone else gives me data that has unclean variable names?
Don’t worry too much, you can easily fix it. My favorite, and the simplest way to do this is using the package janitor, and the function clean_names(). Certainly you could clean your variable names manually, but why? This is really easy.
penguins_clean <- clean_names(penguins_raw)
glimpse(penguins_clean)
#> Rows: 344
#> Columns: 17
#> $ study_name <chr> "PAL0708", "PAL0708", "PAL0708", "PAL0708", "PAL0708…
#> $ sample_number <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 1…
#> $ species <chr> "Adelie Penguin (Pygoscelis adeliae)", "Adelie Pengu…
#> $ region <chr> "Anvers", "Anvers", "Anvers", "Anvers", "Anvers", "A…
#> $ island <chr> "Torgersen", "Torgersen", "Torgersen", "Torgersen", …
#> $ stage <chr> "Adult, 1 Egg Stage", "Adult, 1 Egg Stage", "Adult, …
#> $ individual_id <chr> "N1A1", "N1A2", "N2A1", "N2A2", "N3A1", "N3A2", "N4A…
#> $ clutch_completion <chr> "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "No", "No"…
#> $ date_egg <date> 2007-11-11, 2007-11-11, 2007-11-16, 2007-11-16, 200…
#> $ culmen_length_mm <dbl> 39.1, 39.5, 40.3, NA, 36.7, 39.3, 38.9, 39.2, 34.1, …
#> $ culmen_depth_mm <dbl> 18.7, 17.4, 18.0, NA, 19.3, 20.6, 17.8, 19.6, 18.1, …
#> $ flipper_length_mm <dbl> 181, 186, 195, NA, 193, 190, 181, 195, 193, 190, 186…
#> $ body_mass_g <dbl> 3750, 3800, 3250, NA, 3450, 3650, 3625, 4675, 3475, …
#> $ sex <chr> "MALE", "FEMALE", "FEMALE", NA, "FEMALE", "MALE", "F…
#> $ delta_15_n_o_oo <dbl> NA, 8.94956, 8.36821, NA, 8.76651, 8.66496, 9.18718,…
#> $ delta_13_c_o_oo <dbl> NA, -24.69454, -25.33302, NA, -25.32426, -25.29805, …
#> $ comments <chr> "Not enough blood for isotopes.", NA, NA, "Adult not…You can see that Sample Number became sample_number, Culmen Length (mm) became culmen_length_mm.
The default is to parse with “snake” case, which would look like snake_case. You could also set the argument case to:
"lower_camel"or"small_camel"to get lowerCamel"upper_camel"or"big_camel"to get UpperCamel"screaming_snake"or"all_caps"to get SCREAMING_SNAKE (stop yelling please)"lower_upper"to get lowerUPPER (I don’t know why you’d want this)"upper_lower"to get UPPERlower (I also don’t know why you’d want this)
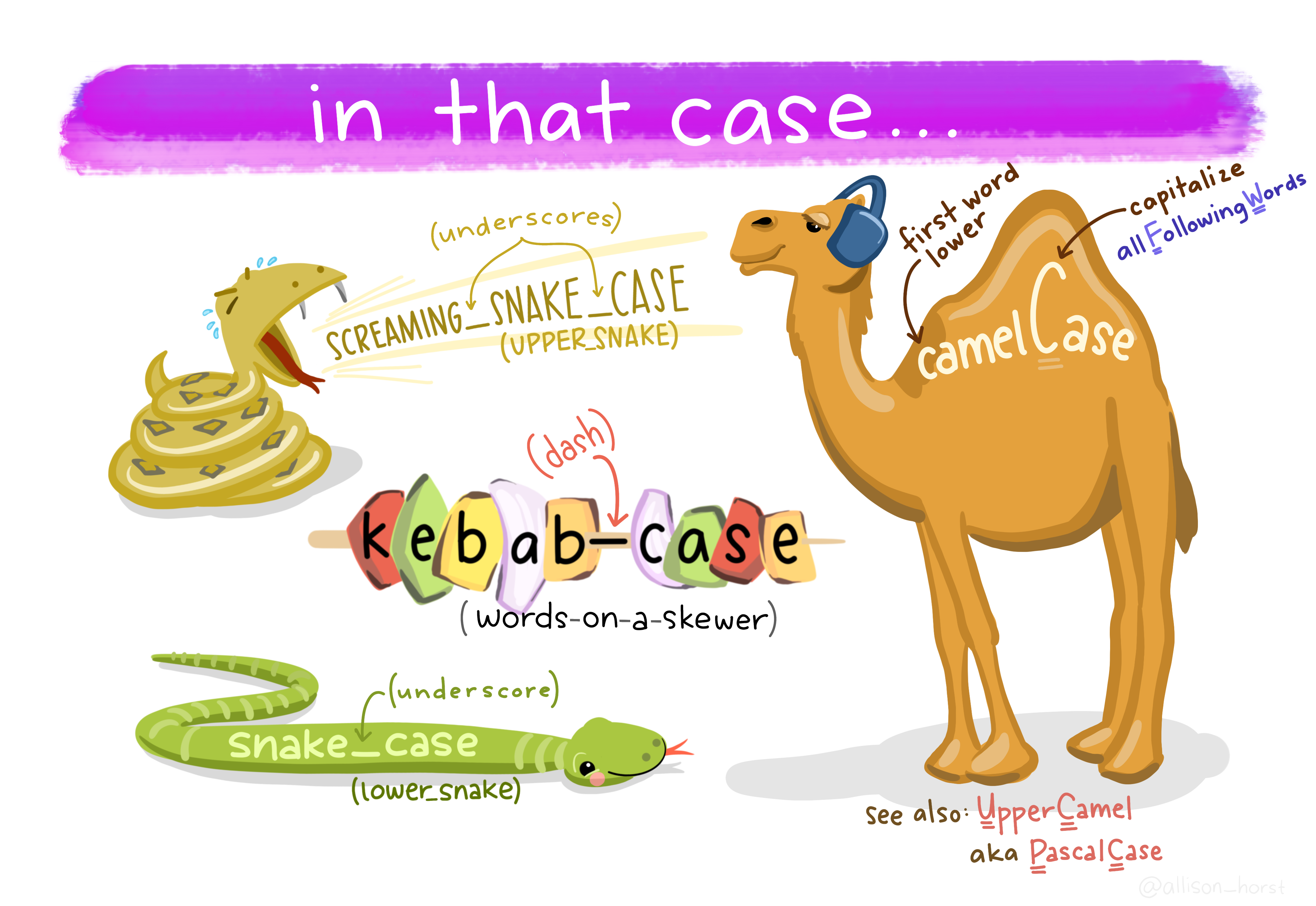
Artwork by Allison Horst
4 - Unite character columns
There will be times when you’d like to take a variable, and combine it with another variable. For example, you might want a column called region_island which contains a combination of the region and island that each penguin is from. We can do this with the function unite(). The function unite() allows you to paste together multiple columns to become one column.
The arguments to unite work like this:
unite(data, col, ..., sep = "_", remove = TRUE, na.rm = FALSE)
penguins_clean_unite <- penguins_clean %>%
unite(col = "region_island",
region:island, # indicate the columns to unite
remove = FALSE) # don't remove region and islandDid it work?
head(penguins_clean_unite)
#> # A tibble: 6 × 18
#> study_name sample_number species region_island region island stage
#> <chr> <dbl> <chr> <chr> <chr> <chr> <chr>
#> 1 PAL0708 1 Adelie Penguin… Anvers_Torger… Anvers Torge… Adult, …
#> 2 PAL0708 2 Adelie Penguin… Anvers_Torger… Anvers Torge… Adult, …
#> 3 PAL0708 3 Adelie Penguin… Anvers_Torger… Anvers Torge… Adult, …
#> 4 PAL0708 4 Adelie Penguin… Anvers_Torger… Anvers Torge… Adult, …
#> 5 PAL0708 5 Adelie Penguin… Anvers_Torger… Anvers Torge… Adult, …
#> 6 PAL0708 6 Adelie Penguin… Anvers_Torger… Anvers Torge… Adult, …
#> # … with 11 more variables: individual_id <chr>, clutch_completion <chr>,
#> # date_egg <date>, culmen_length_mm <dbl>, culmen_depth_mm <dbl>,
#> # flipper_length_mm <dbl>, body_mass_g <dbl>, sex <chr>,
#> # delta_15_n_o_oo <dbl>, delta_13_c_o_oo <dbl>, comments <chr>This is a silly example since there is only one region, but I think you can see how this function is used.
5 - Separate character columns
There will be times that you have a column that has two variables embedded within it, and you will want to separate or parse the column to become two separate columns. You can do this with the function separate().
The arguments to separate look like this:
separate(data, col, into, sep = "yourregex", remove = TRUE, extra = "warn", fill = "warn")
Let’s look at the column stage.
penguins_clean$stage[1:5]
#> [1] "Adult, 1 Egg Stage" "Adult, 1 Egg Stage" "Adult, 1 Egg Stage"
#> [4] "Adult, 1 Egg Stage" "Adult, 1 Egg Stage"We might want to separate the column stage into age and egg_stage. We can do this with separate().
penguins_clean_stage <- penguins_clean %>%
separate(col = stage,
into = c("age", "egg_stage"),
sep = ",", # the comma is the separator
remove = FALSE) Did it work?
penguins_clean_stage %>%
select(stage, age, egg_stage) %>%
head()
#> # A tibble: 6 × 3
#> stage age egg_stage
#> <chr> <chr> <chr>
#> 1 Adult, 1 Egg Stage Adult " 1 Egg Stage"
#> 2 Adult, 1 Egg Stage Adult " 1 Egg Stage"
#> 3 Adult, 1 Egg Stage Adult " 1 Egg Stage"
#> 4 Adult, 1 Egg Stage Adult " 1 Egg Stage"
#> 5 Adult, 1 Egg Stage Adult " 1 Egg Stage"
#> 6 Adult, 1 Egg Stage Adult " 1 Egg Stage"6 - Extract character columns
We can use extract() to set up regular expressions to allow the separation of our variable species into a column with the common name, and a column with the genus species.
We will use str_view to figure out a regex that will work for us.
# indicate our string
string <- "Adelie Penguin (Pygoscelis adeliae)"# to get Adelie Penguin
str_view(string, "\\w+\\s\\w+")
\\wgives you anything that’s a word character- the
+indicates to match alphanumeric at least 1 time \\sindicates a space
# to get Pygoscelis adeliae
str_view(string, "(?<=\\()\\w+\\s\\w+")
(?<=)is called the positive lookbehind, and has this general structure(?<=B)Awhich can be read like “find exprssion A which is preceeded by expression B.” In our example, expression B is a parentheses(. But there is some additional complexity here because parentheses have their own meanings in regex so you need to use the\\to escape them. The whole expression for this part of our regex is(?<=\\().\\wgives you anything that’s a word character- the
+indicates to match alphanumeric at least 1 time \\sindicates a space
Ok our regexs work as desired! Now we can incorporate them into extract(). Here I am using .*? to match the characters between our two targeted regex which here is (.
penguins_clean_extract <- penguins_clean %>%
extract(col = species,
into = c("common_name", "genus_species"),
regex = "(\\w+\\s\\w+).*?((?<=\\()\\w+\\s\\w+)",
remove = FALSE) penguins_clean_extract %>%
select(species, common_name, genus_species) %>%
head()
#> # A tibble: 6 × 3
#> species common_name genus_species
#> <chr> <chr> <chr>
#> 1 Adelie Penguin (Pygoscelis adeliae) Adelie Penguin Pygoscelis adeliae
#> 2 Adelie Penguin (Pygoscelis adeliae) Adelie Penguin Pygoscelis adeliae
#> 3 Adelie Penguin (Pygoscelis adeliae) Adelie Penguin Pygoscelis adeliae
#> 4 Adelie Penguin (Pygoscelis adeliae) Adelie Penguin Pygoscelis adeliae
#> 5 Adelie Penguin (Pygoscelis adeliae) Adelie Penguin Pygoscelis adeliae
#> 6 Adelie Penguin (Pygoscelis adeliae) Adelie Penguin Pygoscelis adeliaeVoila!
7 - Replacing with str_replace()
The column individual_id has two parts: the letter N and then a number, and the letter A and then a number. Let’s split this column into two columns, one called id_n that contains the number after the N, and a second called id_a that contains the number after the A.
penguins_clean_fixID <- penguins_clean %>%
separate(col = individual_id,
into = c("id_n", "id_a"),
sep = "A", # can also use regex "[A]"
remove = FALSE) Did it work?
penguins_clean_fixID %>%
select(individual_id, id_n, id_a) %>%
head()
#> # A tibble: 6 × 3
#> individual_id id_n id_a
#> <chr> <chr> <chr>
#> 1 N1A1 N1 1
#> 2 N1A2 N1 2
#> 3 N2A1 N2 1
#> 4 N2A2 N2 2
#> 5 N3A1 N3 1
#> 6 N3A2 N3 2This worked to separate out the A, but the N is still linked with id_n. We can use a combination of mutate() and str_replace_all() to remove the N. You can learn more about str_replace() here.
penguins_clean_fixID <- penguins_clean_fixID %>%
mutate(id_n = str_replace_all(id_n, "N", ""))penguins_clean_fixID %>%
select(individual_id, id_n, id_a) %>%
head()
#> # A tibble: 6 × 3
#> individual_id id_n id_a
#> <chr> <chr> <chr>
#> 1 N1A1 1 1
#> 2 N1A2 1 2
#> 3 N2A1 2 1
#> 4 N2A2 2 2
#> 5 N3A1 3 1
#> 6 N3A2 3 2Exercises
We will be doing our exercises today with a couple of datasets from the bakeoff package.

Exercise 1
Using the dataset bakers, combine bakers_last with bakers_first to create a new column bakers_last_first which is indicated like this: Lastname, Firstname.
Hints (click here)
Use [`head()`](https://rdrr.io/r/utils/head.html) or `glimpse()` to see the structure of this data. Use `unite()` to combine columns. Don't forget to indicate the correct `sep`Solutions (click here)
head(bakers)
#> # A tibble: 6 × 8
#> series baker_full baker age occupation hometown baker_last baker_first
#> <fct> <chr> <chr> <dbl> <chr> <chr> <chr> <chr>
#> 1 1 "Annetha Mi… Annet… 30 Midwife Essex Mills Annetha
#> 2 1 "David Cham… David 31 Entrepreneur Milton K… Chambers David
#> 3 1 "Edward \"E… Edd 24 Debt collec… Bradford Kimber Edward
#> 4 1 "Jasminder … Jasmi… 45 Assistant C… Birmingh… Randhawa Jasminder
#> 5 1 "Jonathan S… Jonat… 25 Research An… St Albans Shepherd Jonathan
#> 6 1 "Lea Harris" Lea 51 Retired Midlothi… Harris Lea
bakers_2 <- bakers %>%
unite(col = "bakers_last_first",
c(baker_last, baker_first),
sep = ", ")
# did it work?
head(bakers_2)
#> # A tibble: 6 × 7
#> series baker_full baker age occupation hometown bakers_last_fir…
#> <fct> <chr> <chr> <dbl> <chr> <chr> <chr>
#> 1 1 "Annetha Mills" Annetha 30 Midwife Essex Mills, Annetha
#> 2 1 "David Chambers" David 31 Entrepren… Milton … Chambers, David
#> 3 1 "Edward \"Edd\" Kimber" Edd 24 Debt coll… Bradford Kimber, Edward
#> 4 1 "Jasminder Randhawa" Jasminder 45 Assistant… Birming… Randhawa, Jasmi…
#> 5 1 "Jonathan Shepherd" Jonathan 25 Research … St Alba… Shepherd, Jonat…
#> 6 1 "Lea Harris" Lea 51 Retired Midloth… Harris, LeaExercise 2
Using the dataset bakers, convert the column hometown to two columns, where whatever comes before the comma is in a column called city and whatever comes after is in a column called locale.
Hints (click here)
Try using `separate()`.Solutions (click here)
head(bakers)
#> # A tibble: 6 × 8
#> series baker_full baker age occupation hometown baker_last baker_first
#> <fct> <chr> <chr> <dbl> <chr> <chr> <chr> <chr>
#> 1 1 "Annetha Mi… Annet… 30 Midwife Essex Mills Annetha
#> 2 1 "David Cham… David 31 Entrepreneur Milton K… Chambers David
#> 3 1 "Edward \"E… Edd 24 Debt collec… Bradford Kimber Edward
#> 4 1 "Jasminder … Jasmi… 45 Assistant C… Birmingh… Randhawa Jasminder
#> 5 1 "Jonathan S… Jonat… 25 Research An… St Albans Shepherd Jonathan
#> 6 1 "Lea Harris" Lea 51 Retired Midlothi… Harris Lea
bakers_hometown <- bakers %>%
separate(col = hometown,
into = c("city", "locale"),
sep = ", ")
#> Warning: Expected 2 pieces. Additional pieces discarded in 1 rows [71].
#> Warning: Expected 2 pieces. Missing pieces filled with `NA` in 65 rows [1, 2, 3, 4, 5, 7, 8, 11, 12, 15, 19, 20, 23, 25, 27, 28, 31, 34, 38, 41, ...].
# did it work?
head(bakers_hometown)
#> # A tibble: 6 × 9
#> series baker_full baker age occupation city locale baker_last baker_first
#> <fct> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <chr>
#> 1 1 "Annetha M… Annet… 30 Midwife Essex NA Mills Annetha
#> 2 1 "David Cha… David 31 Entrepren… Milt… NA Chambers David
#> 3 1 "Edward \"… Edd 24 Debt coll… Brad… NA Kimber Edward
#> 4 1 "Jasminder… Jasmi… 45 Assistant… Birm… NA Randhawa Jasminder
#> 5 1 "Jonathan … Jonat… 25 Research … St A… NA Shepherd Jonathan
#> 6 1 "Lea Harri… Lea 51 Retired Midl… Scotl… Harris LeaExercise 3
Using the dataset bakers add a column nickname which indicates the bakers nickname, if they have one.
Hints (click here)
Think about how to make a regex that would pull out the nickname. Try using `str_view_all()` to get your regex working before you apply it to `bakers`. Try using the lookahead syntax.Solutions (click here)
baker_full <- bakers$baker_full# note I used single quotes because there were double quotes in the regex
str_view_all(baker_full, '(?<=\\").*(?=\\")') 
bakers_nickname <- bakers %>%
extract(col = baker_full,
into = "nickname",
regex = '((?<=\\")\\w+(?=\\"))')
bakers_nickname %>%
arrange(nickname) %>%
head()
#> # A tibble: 6 × 8
#> series nickname baker age occupation hometown baker_last baker_first
#> <fct> <chr> <chr> <dbl> <chr> <chr> <chr> <chr>
#> 1 1 Edd Edd 24 Debt collector… Bradford Kimber Edward
#> 2 2 Jo Joanne 41 Housewife Ongar, E… Wheatley Joanne
#> 3 7 Val Val 66 Semi-retired, … Yeovil Stones Valerie
#> 4 8 Yan Yan 46 Laboratory res… North Lo… Tsou Chuen-Yan
#> 5 1 NA Annetha 30 Midwife Essex Mills Annetha
#> 6 1 NA David 31 Entrepreneur Milton K… Chambers DavidExercise 4
Using the dataset challenge_results, write a regex to find any signature that contains chocolate. Remove all observations that contain NA for the signature. How many of the signature bakes contain chocolate? What percentage of the total signature bakes (for which we have bake names) does this represent?
Hints (click here)
You can get rid of NAs with `drop_na()`. Try using `str_count()` to see how many occurances you have of chocolate in the signatures.Solutions (click here)
# select only signatures, drop NAs
signatures <- challenge_results %>%
select(signature) %>%
drop_na()
# check dimensions
dim(signatures)
#> [1] 703 1
# regex for chocolate (or Chocolate, or Chocolatey)
str_count(signatures, "[Cc]hocolat[ey]")
#> Warning in stri_count_regex(string, pattern, opts_regex = opts(pattern)): argument is not an atomic vector; coercing
#> [1] 75
# what percent of signatures contain chocolate
(str_count(signatures, "[Cc]hocolat[ey]")/count(signatures))*100
#> Warning in stri_count_regex(string, pattern, opts_regex = opts(pattern)): argument is not an atomic vector; coercing
#> n
#> 1 10.66856