Session 17: Introduction to regular expressions
With help from The Great British Bake Off
 Artwork by @allison_horst
Artwork by @allison_horst
New to Code Club?
-
If you didn’t already do this, please follow the Code Club Computer Setup instructions, which also has pointers for if you’re new to R or RStudio.
-
If you’re able to do so, please open RStudio a bit before Code Club starts – and in case you run into issues, please join the Zoom call early and we’ll help you troubleshoot.
1. Getting set up
While base R also has functions to work with regular expressions (such as grep() and regexp()), we will work with the stringr package, one of the core tidyverse packages.
## If needed, install the tidyverse:
# install.packages("tidyverse")
## Load the tidyverse -- this will include loading "stringr".
library(tidyverse)
To get access to some strings that we can match with regular expressions, we will use the bakeoff data package:
## If needed, first install the "remotes" package:
# install.packages("remotes")
remotes::install_github("apreshill/bakeoff")
2. Regular expressions: what and why?
You would probably have no trouble recognizing internet and email addresses, most phone numbers, or a DNA sequence embedded in a piece of text. And you would do so even if these were presented without context, and even though you may have never seen that specific email address, DNA sequence, and so on.
We can recognize these things because they adhere to certain patterns: a DNA sequence, for instance, typically consists of a sequence of capital As, Cs, Gs, and Ts.
Regular expressions provide a way to describe and match text that contains specific patterns to computers, with expressions that convey things like “any digit” and “one or more or the previous character or character type”. For example, \d{5} is a regular expression that matches at least five consecutive digits and would be a good start to finding all US ZIP codes contained in some text.
Regular expressions are extremely useful for a couple of related purposes:
-
Finding and extracting information that adheres to patterns
-
Finding addresses, citations, or identifiers such as accession numbers.
-
Finding degenerate primers (or the DNA sequence between them) or transcription factor binding sites, in which certain positions may vary.
-
Finding DNA repeats: you know that something is repeated, but not what is.
-
While we often generalize and constrain matches at the same time, we could also merely constrain them:
-
Only find instances of “chocolate” if it is the first or last word of a line/sentence/string.
-
Only find instances of “chocolate” which are followed by “cake”, “tart”, or “croissant”.
-
-
-
Sophisticated find-and-replace
-
Replace multiple variations of the same thing at once:
e.g. change all DNA repeats to lowercase letters or Ns. -
Change a date format from
M/DD/YYtoYYYY-MM-DD, or GPS coordinates in degrees/minutes/seconds format to decimal degrees (note that this needs a bit of conversion too). -
Rename files: switch sample ID and treatment ID separated by underscores,
or pad numbers (1-100=>001-100for proper ordering).
-
Finally, regular expressions can be used to parse and convert file formats, though you generally don’t have to do this yourself unless you are dealing with highly custom file types.
Regular expressions are used in nearly all programming languages. They are also widely used in text editors and therefore provide a first taste of programming for many people.
3. str_view() and strings
Today, to get to know regular expressions, we will just use the str_view() function from the stringr package. Next week, we’ll get introduced to other stringr functions to search and also to replace strings.
The basic syntax is str_view(<target-string(s)>, <search-pattern>), for example:
str_view("chocolate", "cola")
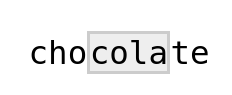
str_view() shows us which part of the target string was matched in the Viewer pane of RStudio. This particular match is rather obvious because we searched for a “literal string” without any special meaning. However, the visual representation will become useful when we start using special characters in our regular expressions: then, we know what pattern we should be matching, but not what exact string we actually matched.
If we want to see all matches, and not just the first one, we have to use str_view_all:
str_view("chocolate", "o")

str_view_all("chocolate", "o")

stringr functions are vectorized, so we can use them not just to match a single string but also to match a vector of strings:
bakes <- c("plum pudding", "chocolate cake", "sticky toffee pudding")
str_view(bakes, "pudding")

Note that the non-matching string “chocolate cake” was displayed despite the lack of a match. If we only want to see strings that matched, we can set the match argument to TRUE:
str_view(bakes, "pudding", match = TRUE)

Strings in R
A “string” or “character string” is a contiguous sequence of characters. To indicate that something is a string in R, we put quotes around it: "Hello" and "9". If you forget the quotes, R would interpret "Hello" as an object (because it starts with a letter) and "9" as a number (because it starts with a digit).
There is no difference between single quotes ('Hello') and double quotes ("Hello"), but double quotes are generally recommended.
If your string is itself supposed to contain a quote symbol of some kind, it is convenient to use the other type of quote to define the string:
# The string contains a single quote, so we use double quotes to define it:
"This cake's 7th layer is particularly good."
#> [1] “This cake’s 7th layer is particularly good."
Alternatively, a quote can be escaped using a backslash \ to indicate that it does not end the string but represents a literal quote inside the string, which may be necessary if a string contains both single and double quotes:
"This cake is only 2'4\" tall - do better!"
#> [1] “This cake is only 2'4" tall - do better!"
4. Special characters
Special characters and escaping them
In regular expressions (regex), we need a way to succinctly convey descriptions such as “any character” or “any digit”. However, there are no characters exclusive to regular expressions: instead, we re-use normal characters. For instance:
- “Any digit” is represented by
\d, with the\basically preventing thedfrom being interpreted literally. - “Any character” is represented by a period,
.
How, then, do we indicate a literal period . in a regular expression? The solution is to escape it with a backslash: the regular expression \. matches a period ..
TLDR for the rest of this section
When writing regular expressions as strings in R, we always need to add an extra backslash:
- The regex
\dmatches a digit — and we write it as"\\d"in R. - The regex
\.matches a period — and we write it as"\\."in R.
The “escaping” described above also applies to backslashes, such that the regex \\ matches a \.
Escape sequences in regular strings
Outside of regular expressions, R also uses backslashes \ to form so-called “escape sequences”. This works similarly to how the regular expression \d means “any digit” – for example, when we use \n in any string, it will be interpreted as a newline:
cat("cho\nco")
#> cho
#> co
In fact, a single backslash \ is never taken literally in any regular R string:
cat("cho\dco")
#> Error: '\d' is an unrecognized escape in character string starting ""cho\d"
Because this is not a regular expression, and \d does not happen to be an escape sequence like \n was earlier, \d doesn’t mean anything to R. But instead of assuming that the backslash is therefore a literal backslash, R throws an error, demonstrating that a backslash is always interpreted as the first character in an escape sequence.
How can we include a backslash in a string, then? Same as before: we “escape” it with another backslash:
cat("bla\\dbla")
#> bla\dbla
The backslash plague
We saw that the regular expression \d matches a digit, but also that using string "\d" will merely throw an error!
Therefore, to actually define a regular expression that contains \d, we need to use the string "\\d":
str_view("The cake has 8 layers", "\d")
#> Error: '\d' is an unrecognized escape in character string starting ""\d"
str_view("The cake has 8 layers", "\\d")
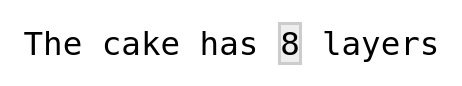
So, to define any regular expression symbol that contains a backslash, we need to always use two backslashes!
This also applies when we want to match a literal character. For example, to match a literal period, we need the regex \., which we have to write as \\. in an R string:
str_view("The cake has 8.5 layers", "\\.")

Now to the worst case: what if we want to match a backslash? We need the regular expression \\, but to define that regex as a string, we have to escape each of the two backslashes – only to end up with four backslashes!
str_view("C:\\Windows", "\\")
#> Error in stri_locate_first_regex(string, pattern, opts_regex = opts(pattern)): Unrecognized backslash escape sequence in pattern. (U_REGEX_BAD_ESCAPE_SEQUENCE, context=`\`)
str_view("C:\\Windows", "\\\\")

Welcome to the backslash plague! 1
5. The Great British Bake Off

Let’s take a look at some of the data in the bakeoff package, which is about “The Great British Bake Off” (GBBO) television show.
The bakers dataframe contains some information about each participant (baker) in the show, and we will be matching names from the baker_full column:
head(bakers)
#> # A tibble: 6 x 8
#> series baker_full baker age occupation hometown baker_last baker_first
#> <fct> <chr> <chr> <dbl> <chr> <chr> <chr> <chr>
#> 1 1 "Annetha Mi… Annet… 30 Midwife Essex Mills Annetha
#> 2 1 "David Cham… David 31 Entrepreneur Milton K… Chambers David
#> 3 1 "Edward \"E… Edd 24 Debt collec… Bradford Kimber Edward
#> 4 1 "Jasminder … Jasmi… 45 Assistant C… Birmingh… Randhawa Jasminder
#> 5 1 "Jonathan S… Jonat… 25 Research An… St Albans Shepherd Jonathan
#> 6 1 "Lea Harris" Lea 51 Retired Midlothi… Harris Lea
The challenge_results dataframe contains “signature” and “showstopper” bakes made by each participant in each episode:
head(challenge_results)
#> # A tibble: 6 x 7
#> series episode baker result signature technical showstopper
#> <int> <int> <chr> <chr> <chr> <int> <chr>
#> 1 1 1 Annet… IN Light Jamaican … 2 Red, White & Blue Cho…
#> 2 1 1 David IN Chocolate Orang… 3 Black Forest Floor Ga…
#> 3 1 1 Edd IN Caramel Cinnamo… 1 NA
#> 4 1 1 Jasmi… IN Fresh Mango and… NA NA
#> 5 1 1 Jonat… IN Carrot Cake wit… 9 Three Tiered White an…
#> 6 1 1 Louise IN Carrot and Oran… NA Never Fail Chocolate …
The “signature” bakes are the first bakes presented in each GBBO episode, so we’ll start trying to match these bakes with regular expressions. Let’s save them in a vector for easy access later on:
signatures <- challenge_results$signature # Assign the column to a vector
signatures <- signatures[!is.na(signatures)] # Remove NAs
signatures[1:20] # Look at the first 20 items
#> [1] "Light Jamaican Black Cakewith Strawberries and Cream"
#> [2] "Chocolate Orange Cake"
#> [3] "Caramel Cinnamon and Banana Cake"
#> [4] "Fresh Mango and Passion Fruit Hummingbird Cake"
#> [5] "Carrot Cake with Lime and Cream Cheese Icing"
#> [6] "Carrot and Orange Cake"
#> [7] "Triple Layered Brownie Meringue Cake\nwith Raspberry Cream"
#> [8] "Three Tiered Lemon Drizzle Cakewith Fresh Cream and freshly made Lemon Curd"
#> [9] "Cranberry and Pistachio Cakewith Orange Flower Water Icing"
#> [10] "Sticky Marmalade Tea Loaf"
#> [11] "Cheddar Cheese and Fresh Rosemary Biscuits"
#> [12] "Oatmeal Raisin Cookie"
#> [13] "Millionaires' Shortbread"
#> [14] "Honey and Candied Ginger Cookies"
#> [15] "Fresh Vanilla Biscuits with Royal Icing"
#> [16] "Peanut Shortbread withSalted Peanut Caramel"
#> [17] "Rose Petal Shortbread"
#> [18] "Stained Glass Window Shortbread"
#> [19] "Chilli Bread"
#> [20] "Olive Bread"
6. Components of regular expressions
Literal characters
Literal characters can be a part of regular expressions. In fact, as we saw in the first example, our entire search pattern for str_view() can perfectly well consist of only literal characters.
But the power of regular expressions comes with special characters, and below, we’ll go through several different categories of these.
Metacharacters
Metacharacters often represent a single instance of a character type: above, we already learned that . matches any single character.
Other metacharacters are actually character combinations starting with a \:
| Symbol | Matches | Negation (“anything but”) |
|---|---|---|
. |
Any single character. | |
\d |
Any digit. | \D |
\s |
Any white space: space, tab, newline, carriage return. | \S |
\w |
Any word character: alphanumeric and underscore. | \W |
\n |
A newline. | |
\t |
A tab. |
Negated metacharacters match anything except that character type: \D matches anything except a digit.
Some examples:
-
Are there any digits (
\d) in the bake names?str_view_all(signatures, "\\d", match = TRUE)
-
Let’s match 5-character strings that start with “Ma":
str_view_all(signatures, "Ma...", match = TRUE)
Note that the only constraint we are setting with
...is that at least three characters should followMa– we are not restricting matches to five-character words.
-
Let’s find the bakers whose (first or last) names contain at least 11 word characters
\w:str_view_all(bakers$baker_full, "\\w\\w\\w\\w\\w\\w\\w\\w\\w\\w\\w", match = TRUE)
It’s not very convenient to have to repeat
\\wso many times!
Or let’s say we wanted to get all three-part names: names that contain three sets of one or more word characters separated by non-word characters. How could we describe such a pattern? “Quantifiers” to the rescue!
Quantifiers
Quantifiers describe how many consecutive instances of the preceding character should be matched:
| Quantifier | Matches |
|---|---|
* |
Preceding character any number of times (0 or more). |
+ |
Preceding character at least once (1 or more). |
? |
Preceding character at most once (0 or 1). |
{n} |
Preceding character exactly n times. |
{n,} |
Preceding character at least n times. |
{n,m} |
Preceding character at least n and at most m times. |
Some examples:
-
Names with at least 11 (
{11,}) characters – note that this matches the entire word:str_view(bakers$baker_full, "\\w{11,}", match=TRUE)
-
Match names with 2 to 3 (
{2,3}) consecutive “e” characters. Note that this match encompasses the full string (name), because we flank the pattern with.*.str_view(bakers$baker_full, ".*e{2,3}.*", match=TRUE)
-
Account for different spelling options with
?– match “flavor” or “flavour":str_view_all(signatures, "flavou?r", match=TRUE)
-
Match all three-part names – one or more word characters (
\w+) separated by a non-word character (\W) at least two consecutive times:str_view(bakers$baker_full, "\\w+\\W\\w+\\W\\w+", match=TRUE)
-
Match all three-letter names by looking for non-word characters (
\W) surrounding three word characters (\w{3})?str_view_all(bakers$baker_full, "\\W\\w{3}\\W", match = TRUE)
That last attempt didn’t really work – note that we only got three-letter middle names, since we required our three-letter names to be flanked by non-word characters.
To get all three-letter names, we need to be able to “anchor” our regular expressions, e.g. demand that a pattern starts at the beginning of the string.
Anchors
| Anchor | Matches |
|---|---|
^ |
Beginning of the string/line |
$ |
End of the string/line |
\b |
A word boundary (beginning or end) |
Some examples:
-
Match all three-letter first names, by anchoring the three word characters (
\w{3}) to the beginning of the string with^, and including a space at the end:str_view(bakers$baker_full, "^\\w{3} ", match = TRUE)
-
Match all three-letter names –whether first, middle, or last– using three word-characters (
\w) surrounded by word-boundaries (\b):str_view_all(bakers$baker_full, "\\b\\w{3}\\b", match = TRUE)
Regex components for next week
Next week, we’ll talk about:
- Character classes
- Alternation
- Grouping
- Backreferences
- Making quantifiers non-greedy
Regular expressions vs globbing
Do not confuse regular expressions with globbing!
If you have worked in a terminal before, you may know that you can match file names using shell wildcards, which is known as “globbing”.
There are only a few characters used in shell wildcards, but their meanings differ from regular expressions in two instances!
| Shell wildcard | Equivalent regex | Meaning |
|---|---|---|
? |
. |
Any single character |
* |
.* |
Any number of any character |
[] and [^] |
same! | Match/negate match of character class |
- Note also that
.is interpreted as a literal period in globbing. - We will talk about “character classes” next week.
7. Breakout rooms
Exercise 1
Find all participant names in bakers$baker_full that contain at least 4 lowercase “e” characters. (That, the “e“s don’t need to be consecutive, but you should not disallow consecutive “e“s either.)
Hints
Use .* to allow for optional characters in between the “e"s.
Solution
str_view(bakers$baker_full, "e.*e.*e.*e", match = TRUE)

Exercise 2
In the signatures vector, match words of exactly five characters that start with “Ta”.
Hints
-
To describe the five-letter word you should include three word characters after “Ta”.
-
To exclusively match five-letter words, you should use the “word boundary” anchor before and after the part that should match the word.
Solution
str_view_all(signatures, "\\bTa\\w{3}\\b", match = TRUE)

Exercise 3
Match “Donut” as well as “Doughnut” in the signatures vector.
Unfortunately, signatures only contains the spelling “Doughnut”. Therefore, you should separately test whether your regex would actually match “Donut”.
Hints
Since “donut” is contained within “doughnut”, you can build a single regex and use ? to indicate optional characters.
Solution
str_view_all(signatures, "Dou?g?h?nut", match=TRUE)

str_view_all(c(signatures, "Donut"), "Dou?g?h?nut", match=TRUE)

Exercise 4
Match both dates in the string: “The best cakes were baked between 2016-03-10 and 2017-08-31.”.
Hints
Make sure you use str_view_all() and not str_view()!
Solution
mystring <- "The best cakes were baked between 2016-03-10 and 2017-08-31."
str_view_all(mystring, "\\d{4}-\\d{2}-\\d{2}")
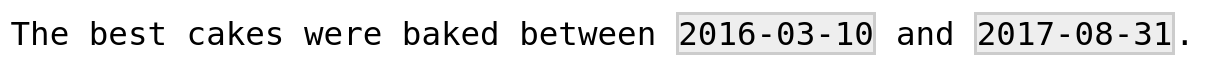
Bonus exercise
You can use the list.files() function in R to list files on your computer. list.files() takes an argument pattern to which you can specify a regular expression in order to narrow down the results.
For example, the code below would find all files with “codeclub” in the name, from your current working directory (the default for the path argument) and downwards (due to recursive = TRUE):
list.files(pattern = "codeclub", recursive = TRUE)
You can also specify a path – for instance, the code below would search your home or (on Windows) Documents directory and nothing below it:
list.files(path = "~", pattern = "codeclub") # "~" is your home dir
list.files(path = "C:/Users/myname/Documents", pattern = "codeclub")
Use this function to list only R scripts, i.e. files ending in .R, in a directory of your choice.
Hints
Make sure to use the “end of string” anchor.
Solution
Here we are searching the the home dir and everything below it – could take a while, but then you know how many R scripts you actually have!
list.files(path = "~", pattern = "\\.R$", recursive = TRUE)
8. Further resources
-
The chapter on strings in Hadley Wickham’s R for Data Science (freely abailable online!).
-
A course video by Roger Peng introducing regular expressions.
-
RegExplain, an RStudio add-in to visualize regex matches and help build regular expressions.
-
Since R 4.0, which was released last year, there is also a “raw string” or “raw character constant” construct, which circumvents some of these problems – see this blogpost that summarizes this new syntax. Because many are not yet using R 4.x, and most current examples, vignettes, and tutorials on the internet don’t use this, we will stick to being stuck with all the backslashes for now. ↩︎