Session 9: Subsetting
Overview of subsetting data structures in R.
New To Code Club?
-
First, check out the Code Club Computer Setup instructions, which also has some pointers that might be helpful if you’re new to R or RStudio.
-
Please open RStudio before Code Club to test things out – if you run into issues, join the Zoom call early and we’ll troubleshoot.
Session Goals
- Learn the uses of R’s three basic subsetting operators:
[ ],[[ ]], and$. - Learn how the behavior of these operators varies depending on the data structure you are subsetting (vector, matrix, list, or data frame).
- Prepare to learn how these resemble, and differ from, subsetting operators in Python.
Intro: What is ‘subsetting’ anyway?
Subsetting (also known as indexing) is simply a formal way of pulling out specific pieces of a data structure. We’ve already seen two dplyr verbs that perform this kind of operation for tibbles: filter (to pull out specific rows) and select (to pull out specific columns).
But these are tidyverse commands, and only work with tibbles. R has two more-basic data structures, vectors and lists, and for these we need different subsetting operators. We’ll also see that matrices are simply a special kind of vector, that data frames are a special kind of list, and basic subsetting operators also work for these.
Since the behavior of these operators depends on the actual data structure you are working with, it’s useful when experimenting to use them in conjunction with the str() function, which compactly displays the internal structure of an arbitrary R object. A knowledge of the make-up of these data structures is also important when you come to write your own loops, iterations, and functions.
The most important distinction between vectors and lists is that vectors are homogeneous, while lists can be heterogeneous.
Terminological note: ‘under-the-hood’ both of these are vectors in the technical sense, and sometimes the distinction is referred to as atomic vectors versus recursive vectors. I’ll continue to use just ‘vector’ and ‘list’ here. This usage also lines-up with Python.
Vectors
A vector is absolutely the most basic data structure in R. Every value in a vector must be of the same type. Strikingly, this sets R apart from Python. Using this kind of vector in Python requires loading a whole separate package: numpy. The most basic data structure in Python is the list.
There are four basic types of vector: integer, double, character, and logical. Vectors are created by hand with the c() (combine, concatenate) function. We can check the type with the typeof() operator. This is totally redundant if you just created the vector yourself, but when you are debugging code or creating a vector using an expression you might want to check exactly what type of vector is being used:
vec_which2 <- 1:10
typeof(vec_which2)
#> [1] "integer"
What happens when we perform a basic mathematical operation on a vector?
2 * vec_int
#> [1] 2 4 6 8 10
(This is completely different than what you obtain when multiplying a Python list).
L = [1, 2, 3, 4, 5]
2 * L
# [1, 2, 3, 4, 5, 1, 2, 3, 4, 5]
So it’s not just that vectors are a basic R data structure, but R is a vectorised language. In many cases applying an operation to a vector automagically applies the operation to every element in the vector. This means that for many basic operations for loops and mapping functions, necessary in Python, are not needed in R (although if you write your own functions you will need these iteration tools). In Python we could use a ‘list comprehension’ (a compact and fast version of a for loop):
[2 * i for i in L]
# [2, 4, 6, 8, 10]
Or install the numpy package that makes vectors and vectorized functions available.
Vectors have an insanely simple structure:
str(vec_dbl)
#> num [1:5] 1 2 3 4 5
str() also displays the type, and RStudio displays the result of str() in the Values pane.
For such a simple structure, there are a surprisingly large number of ways to subset a vector. We’ll use the following example:
x <- c(2.1, 4.2, 3.3, 5.4)
(Notice that the number after the decimal point indicates the position (index) of the element of the vector.)
Positive integers return elements at the specified positions. Any expression that evaluates to a vector of positive integers can be used as the index. The index operator is []:
(In R the indices run from 1 to the length of the object: in Python indices run from 0 to length-1).
Negative integers exclude elements at the specified positions:
x[-3]
#> [1] 2.1 4.2 5.4
x[-c(3, 1)]
#> [1] 4.2 5.4
#> [1] 4.2 5.4
Logical vectors select elements where the corresponding logical value is TRUE. This is most useful if you can write a comparison expression 2 > 3, 4 == 4, that returns TRUE (or FALSE) for each element of the vector:
x[c(TRUE, TRUE, FALSE, FALSE)]
#> [1] 2.1 4.2
x[x > 3]
#> [1] 4.2 3.3 5.4
Attributes. One of the unusual features of R as opposed to Python is that you can assign metadata of various kinds to the elements of vectors (and lists). For example, we can assign a name to each element, and then use a character vector as the index expression:
y <- c(a = 2.1, b = 4.2, c = 3.3, d = 5.4)
str(y)
#> Named num [1:4] 2.1 4.2 3.3 5.4
#> - attr(*, "names")= chr [1:4] "a" "b" "c" "d"
y[c("d", "c", "a")]
#> d c a
#> 5.4 3.3 2.1
(Again, Python has no direct equivalent of this, but we can get a similar effect using a dictionary data structure, which explicitly assigns a name to each value).
Nothing ([]) returns the entire vector:
x[]
#> [1] 2.1 4.2 3.3 5.4
This is not useful for (one dimensional) vectors, but is behind the notation for extracting rows and columns from matrices. Keep in mind a “nothing” index returns “everything”.
Matrices
A matrix is simply a vector with a dimensions attribute. Here we convert a vector to a two-dimensional matrix, with two rows and three columns, with dim(rows, cols).
z <- c(2.1, 4.2, 3.3, 5.4, 8.5, 1.6)
dim(z) <- c(2, 3)
z
#> [,1] [,2] [,3]
#> [1,] 2.1 3.3 8.5
#> [2,] 4.2 5.4 1.6
Now we can index a specific value using comma notation, where the first index specifies the row, and the second index the column (in Python this is reversed):
z[2,3]
#> [1] 1.6
And in two dimensions the nothing after the , returns every column for that row:
z[2,]
#> [1] 4.2 5.4 1.6
And here is a way of selecting a submatrix (every row for all columns except the first):
z[,-1]
#> [,1] [,2]
#> [1,] 3.3 8.5
#> [2,] 5.4 1.6
Lists
There are two main differences between vectors and lists: (i) lists can contain elements of different types; and (ii) lists can contain other lists. This is why lists are sometimes referred to as recursive vectors. We will see examples of these below, but first let’s directly compare a list of numbers to a vector of numbers, and examine the structure. Lists are constructed with the list() function.
l <- list(2.1, 4.2, 3.3, 5.4)
l
#> [[1]]
#> [1] 2.1
#>
#> [[2]]
#> [1] 4.2
#>
#> [[3]]
#> [1] 3.3
#>
#> [[4]]
#> [1] 5.4
str(l)
#> List of 4
#> $ : num 2.1
#> $ : num 4.2
#> $ : num 3.3
#> $ : num 5.4
Here we see the appearance of a new subsetting operator [[ ]]. What does it yield?
ll_2 <- l[[2]]
ll_2
#> [1] 4.2
typeof(ll_2)
#> [1] "double"
Now compare this to the result of using the [ ] operator:
The behavior of the [ ] operator is very different for lists: it selects the element(s) you request, but it always returns a subsetted version of the original list. It ‘shrinks’ the original list. There is nothing like this in Python; it’s quite unique to R. (The reason this is the case will become clear when we examine data frames.) The [[ ]] operator on the other hand just returns the object you select.
As mentioned above, it’s quite possible that an element of a list might itself be a list:
m <- list(2.1, list(4.21, 4.22), 3.3, 5.4)
m
#> [[1]]
#> [1] 2.1
#>
#> [[2]]
#> [[2]][[1]]
#> [1] 4.21
#>
#> [[2]][[2]]
#> [1] 4.22
#>
#>
#> [[3]]
#> [1] 3.3
#>
#> [[4]]
#> [1] 5.4
This (print) output focuses on content, whereas the str() function focuses on structure, and is very useful for nested lists:
str(m)
#> List of 4
#> $ : num 2.1
#> $ :List of 2
#> ..$ : num 4.21
#> ..$ : num 4.22
#> $ : num 3.3
#> $ : num 5.4
Once we combine nested lists and multiple types, things can get pretty hairy. There are various ways to visualize what’s going on. Here is one example:
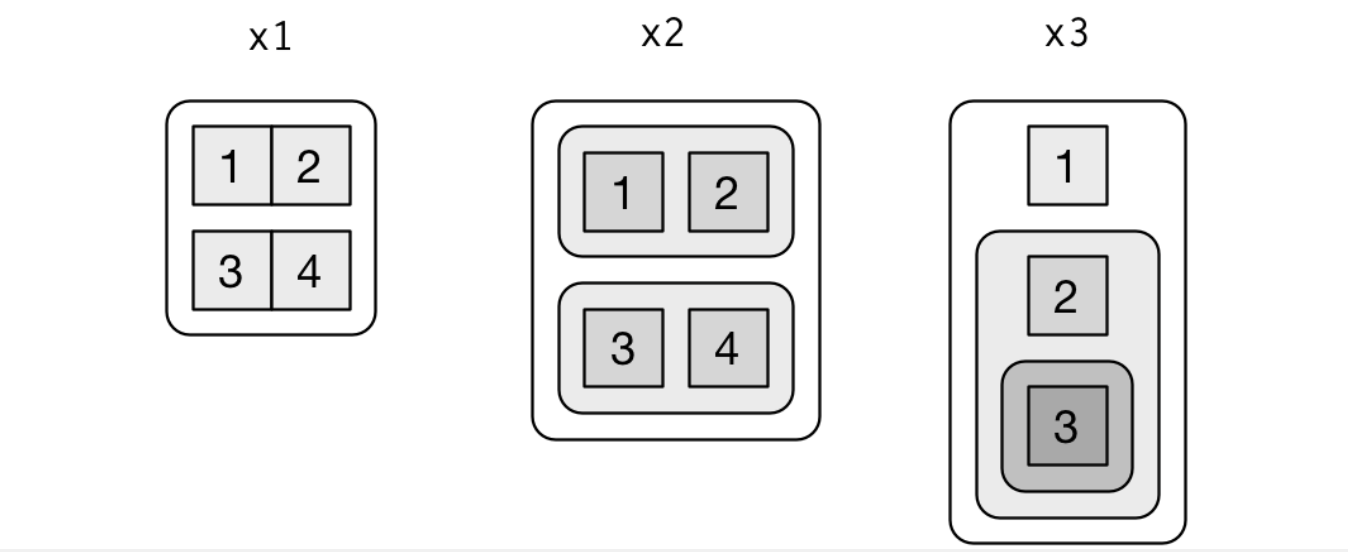
However the printed form provides us a clue on how to extract an individual element from inside a nested list:
# m <- list(2.1, list(4.21, 4.22), 3.3, 5.4)
m[[2]]
#> [[1]]
#> [1] 4.21
#>
#> [[2]]
#> [1] 4.22
m[[2]][[1]]
#> [1] 4.21
In short, [[ ]] drills down into a list, while [ ] returns a diminished version of the original list.
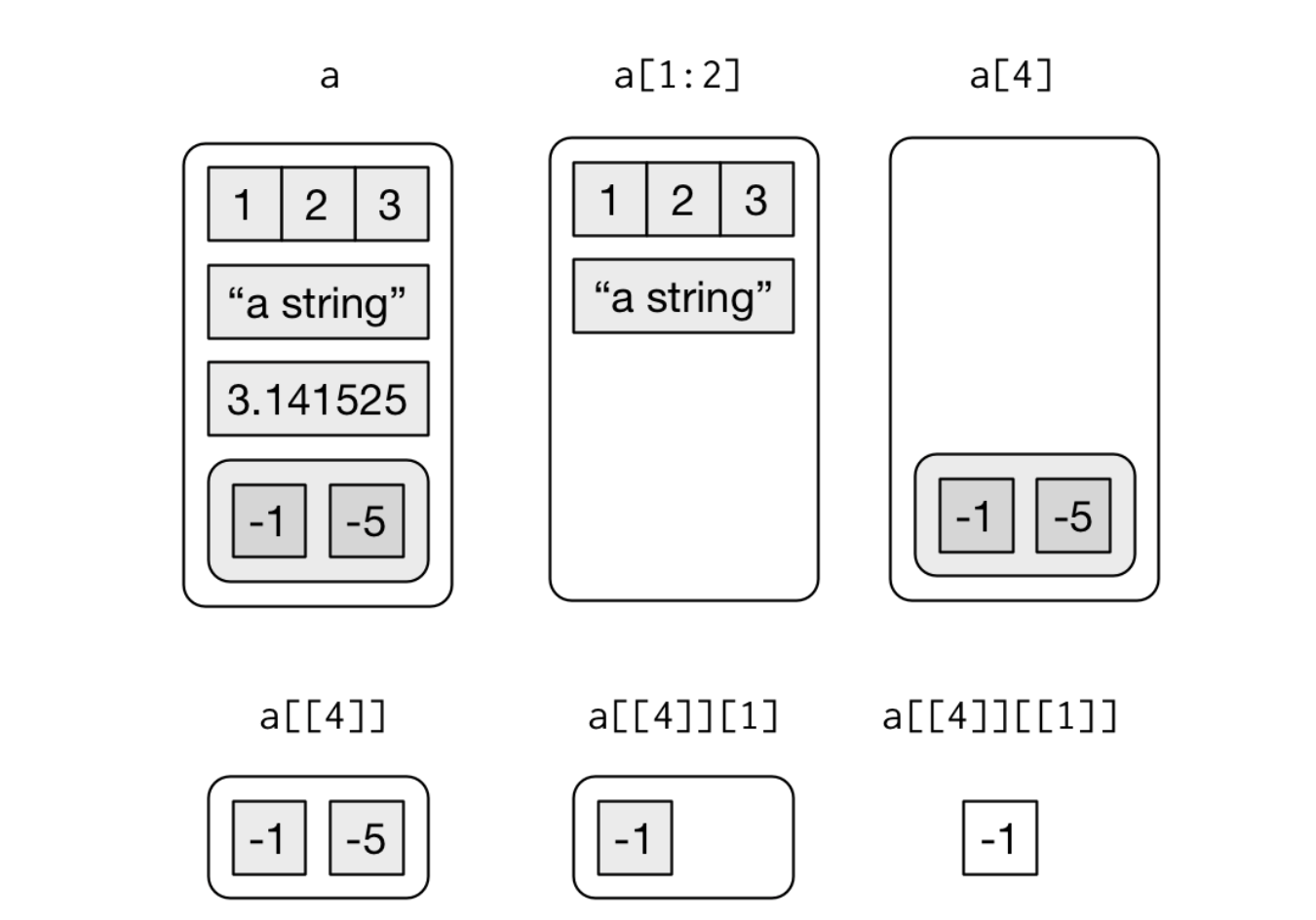
Here’s a visualization of various list subsetting operations:
a <- list(1:3, "a string", pi, list(-1, -5))
a
#> [[1]]
#> [1] 1 2 3
#>
#> [[2]]
#> [1] "a string"
#>
#> [[3]]
#> [1] 3.141593
#>
#> [[4]]
#> [[4]][[1]]
#> [1] -1
#>
#> [[4]][[2]]
#> [1] -5
str(a)
#> List of 4
#> $ : int [1:3] 1 2 3
#> $ : chr "a string"
#> $ : num 3.14
#> $ :List of 2
#> ..$ : num -1
#> ..$ : num -5
Here is a recursive pepper shaker, p
Here is the first packet, but still inside the shaker, p[1]
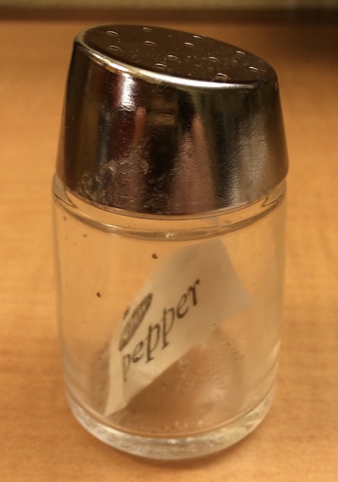
Here is the first packet by itself, p[[1]]

And here is the contents of that packet, p[[1]][[1]]

We’ll play with yet another type of visualization in the exercises.
Data frames
Let’s look at a simple data frame:
df <- data.frame(x = 1:3, y = c("a", "b", "c"))
typeof(df)
#> [1] "list"
str(df)
#> 'data.frame': 3 obs. of 2 variables:
#> $ x: int 1 2 3
#> $ y: chr "a" "b" "c"
So a data frame is basically a list (of columns), with a names attribute for the column names; and with the extra condition that all the columns are of the same length. So we should be able to use our standard list subsetting operators on it:
df_col_1 <- df[1]
str(df_col_1)
#> 'data.frame': 3 obs. of 1 variable:
#> $ x: int 1 2 3
Since a data frame is a list, subsetting using [ ] returns the specified column still inside a data frame. What about [[ ]]?
col_1 <- df[[1]]
str(col_1)
#> int [1:3] 1 2 3
Using [[ ]] returns the individual column.
We can also subset a data frame by name:
df_name <- df["x"]
str(df_name)
#> 'data.frame': 3 obs. of 1 variable:
#> $ x: int 1 2 3
df_nname <- df[["x"]]
str(df_nname)
#> int [1:3] 1 2 3
Finally df$x is simply a shorthand for df[["x"]] without the [[ ]] and the " ":
df_dollar_name <- df$x
str(df_dollar_name)
#> int [1:3] 1 2 3
Just as a matter of interest, in the grand scheme of things lists are just a special kind of vector (a ‘heterogeneous recursive vector’), so it should be possible to stick a list column into a data frame. We can, but we have to use the I ‘identity’ operator around the list:
df_mixed <- data.frame(
x = 1:3,
y = I(list(4L, 7.2, "string")))
str(df_mixed)
#> 'data.frame': 3 obs. of 2 variables:
#> $ x: int 1 2 3
#> $ y:List of 3
#> ..$ : int 4
#> ..$ : num 7.2
#> ..$ : chr "string"
#> ..- attr(*, "class")= chr "AsIs"
Further reading and acknowledgement
For more details on subsetting see R for Data Science and Advanced R both by Hadley Wickham, from which much of the material in this module was borrowed.
Exercise 1
A surprisingly useful operator for extracting elements of a numerical vector is the modulo operator x %% y. This returns the remainder when x is divided by y. It is a vectorized operation, so we can apply it to a list.
x <- c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
x %% 3
#> [1] 1 2 0 1 2 0 1 2 0 1
Use this operator to extract every third element of the above vector x.
Hints (click here)
Check the example in the presentation about selecting elements when the logical comparison is TRUE. What is the logical test we need to identify every third element?
Exercise 2
Here is a visualization of a list:

Create a list in R called train that captures this structure. Print the list, and also display its structure.
Hints (click here)
This list has no nested lists, it’s just a list of vectors and individual values.
Exercise 3
For each of the following sub-trains/carriages, determine the subsetting expression by eye, and then check that it works by subsetting your train list from exercise 1.

Hints (click here)
There's more than one way to do these; you will have to use both `[ ]` and `[[ ]]` operators. The last two are tricky, experiment with them...
Solution (click here)
train[1]
#> [[1]]
#> [1] 1 2 3
train[[1]]
#> [1] 1 2 3
train[1:2]
#> [[1]]
#> [1] 1 2 3
#>
#> [[2]]
#> [1] "a"
train[-2]
#> [[1]]
#> [1] 1 2 3
#>
#> [[2]]
#> [1] 4 5 6
train[c(1, 1)]
#> [[1]]
#> [1] 1 2 3
#>
#> [[2]]
#> [1] 1 2 3
train[0]
#> list()
Exercise 4
A common use of recursive structures in biology is to represent phylogenetic trees. Create a recursive list in R called tree which captures the following visual representation
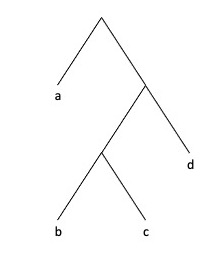
Hints (click here)
Start at the top and work down. Start with a simpler subtree, then expand terminals.
Alternatively, start at the bottom with the smallest subtree, then work up, adding sisters into parent nodes.
In either case, check your working with str() as you incrementally add structure.
Notice this is a binary branching tree, so the root node of every subtree should contain two elements.
One of the tricks with these nested lists is to keep track of paired parentheses…
Stay calm and recurse.